Introduction
Si vous avez l’habitude de travailler sur des projets informatiques, vous avez sans doute déjà entendu parler d’intégration continue. Cette dernière est une méthode de travail qui consiste à vérifier chacune des modifications faite dans le code source, afin que n’apparaissent pas les éventuelles régressions dans votre application.
Il y a deux différentes manières de vérifier et tester du code :
- manuellement : on passe donc forcément par la lecture du code, via les merge request ou pull request afin de comparer l’ancienne et la nouvelle version. Et, si besoin on déploie l’application en local ou sur un serveur de test, avec le nouveau code source poru vérifier en grandeur nature ce que donne ce changement.
- automatiquement : Il est tout à fait possible de déléguer certaines vérifications, ou tests à un système tiers, qui, avec des règles que vous lui aurez définies en amont, va exécuter une batterie de commandes, et vérifier sans que vous n’ayez besoin de lever le petit doigt que votre nouveau code est sain. C’est ce qu’on nomme l’intégration continue, en anglais continuous integration (CI). Ces commandes se déclencheront sur les serveurs de gitlab, quand un push sera effectué sur la ou les branches que vous aurez définies. Ainsi, vous pourrez contrôler tout ce qui transite dans votre repository. Ces commandes s’appellent les pipelines
Ça a l’air bien beau et Intéressant ça, mais… Comment on fait ?
C’est ici que Gitlab CI intervient :
Initialisation de notre projet dans gitlab
Création du projet
Avant toute chose, pour mettre en place de l’intégration continue sur Gitlab, il nous faut bien évidemment un projet versionné avec GIT. Dans un précédent article, je vous expliquais comment mettre en place une application PHP-apache-mysql sour docker. Je vous propose de reprendre ce petit site, sur lequel nous allons initialiser notre CI.
Je vous laisse le télécharger en cliquant ICI.
Rappel : Si vous n’avez pas lu cet article, la finalité est simplement d’avoir une base de site prêt à l’empli, se lançant avec Docker. Pour lancer rapidement le site :
1) Télécharger le zip et dé-zippez le
2) Ouvrez un terminal dans ce dossier et lancez la commande « $ docker-compose up »
3) Une fois que les containers sont lancés, rendez-vous sur http://localhost
Une fois le projet lancé, rendez-vous sur le seul fichier PHP de l’application, et remplacez le contenu par ce dernier, afin d’avoir un projet vierge :
<?php
echo 'Hello World';Si tout se passe correctement, votre localhost devrait vous afficher ce texte.
Versionnement du projet sur Gitlab
Étant donné que les pipelines que nous allons demander de s’effectuer se lanceront sur les serveurs de Gitlab, il faut nous faut donc versionner notre projet avec GIT. Faisons-le tout simplement :
- Si ce n’est pas déjà fait, créez vous un compte Gitlab
- Une fois cela fait, rendez-vous sur la liste des projets et créez en un nouveau :
- Choisissez l’option « Create blank project »
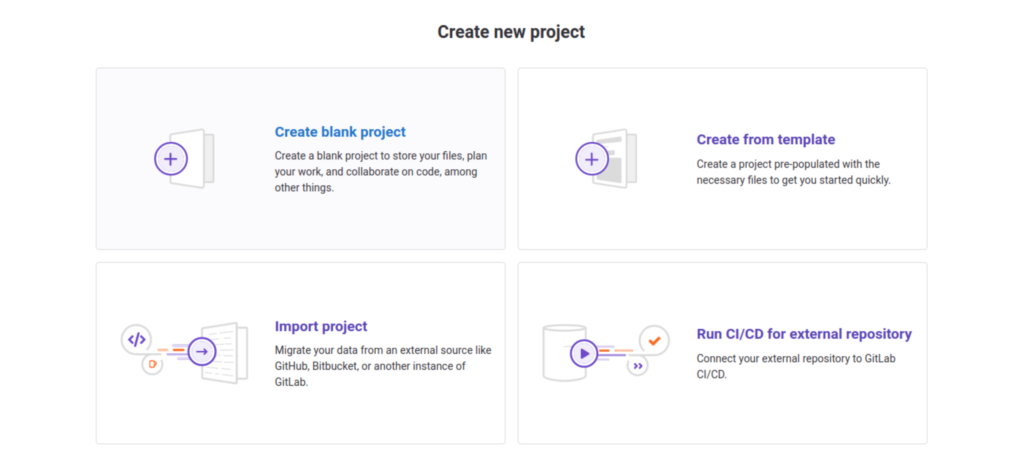
- Donnez lui le nom que vous souhaitez, puis finalisez sa création
- Exécutez ces commandes sur votre PC
$ cd <VOTRE_DOSSIER>
$ git clone origin <URL_DU_PROJET_.git>Vous trouverez l’URL de votre repository en appuyant sur le bouton « Clone », et en copiant la valeur de la section « Clone with HTTPS » :
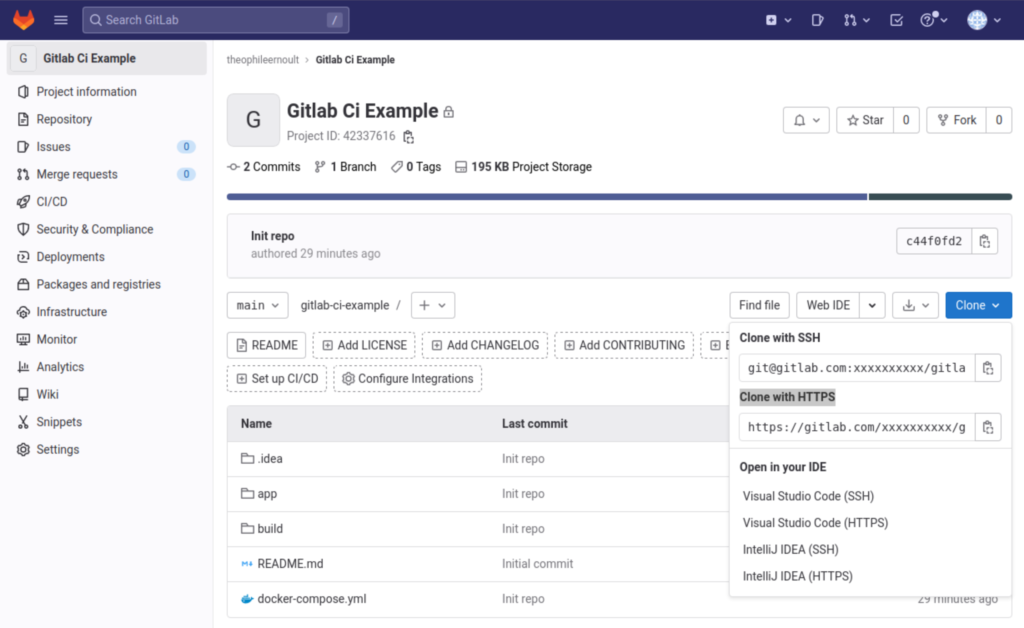
Nous avons cloné le projet en local, mais il est vide. Dé-zippez dans ce dossier les éléments que vous avez téléchargé, puis lancez ces commandes :
$ git add .
$ git commit -m 'Init repo'
$ git push -origin mainUne fois tout ceci fait, vous devriez, comme sur la capture d’écran précédente, vous retrouver avec le projet complet, versionné sur Gitlab. Nous allons pouvoir commencer à entrer dans le vif du sujet, c’est à dire à commencer l’intégration continue !
Mise en place de l’intégration continue
.gitlab-ci.yml
Maintenant que tout est prêt, nous allons pouvoir débuter. Tout d’abord, n’importe quelle règle qui doit être mise en place, le sera par l’intermédiaire d’un fichier que vous devrez placer à la racine de votre repository et qui se nommera « .gitlab-ci.yml ». Je vous propose de le créer tout de suite, en prenant un template des plus basiques, proposé d’ailleurs par Gitlab :
stages: # List of stages for jobs, and their order of execution
- test
unit-test-job: # This job runs in the test stage.
stage: test
script:
- echo "Running unit tests... This will take about 60 seconds."
- sleep 60
- echo "Code coverage is 90%"
lint-test-job: # This job also runs in the test stage.
stage: test # It can run at the same time as unit-test-job (in parallel).
script:
- echo "Linting code... This will take about 10 seconds."
- sleep 10
- echo "No lint issues found."
Qu’est-ce que contient ce fichier ?
- Nous définissons 1 étape qui se lancera à chaque push, que nous appellons « test »
- Pour cette étape de test, nous définissions 2 jobs, « unit-test-job » et « lint-test-job », qui exécuteront les commandes définies à l’intérieur.
Voilà, pour le moment ce n’est pas très sorcier n’est-ce pas ? Versionnez le tout et envoyez le fichier sur Gitlab :
$ git commit -am 'Add gitlab CI'
$ git push origin mainLes pipelines
Rendez-vous sur Gitlab dans la rubrique CI/CD > Pipelines, et vous allez vous apparaître une entrée, correspondant à votre fichier fraîchement commité :
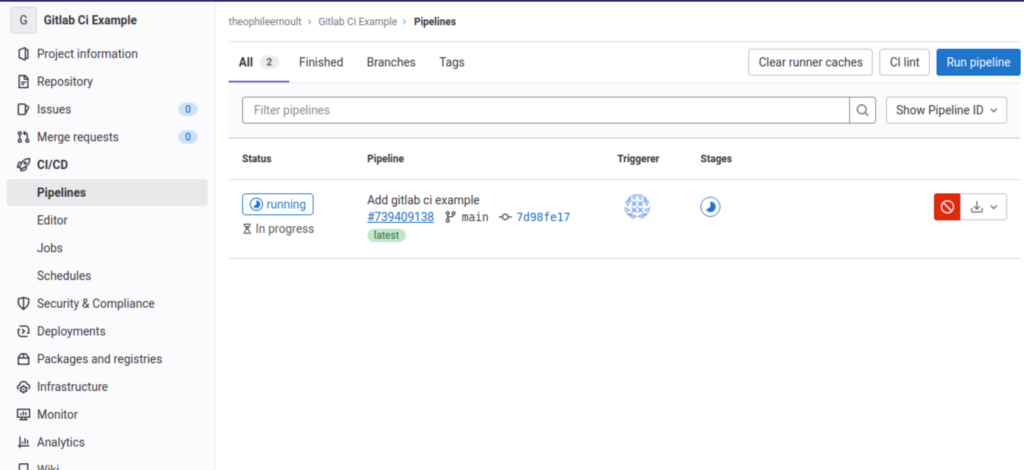
Votre pipeline est en cours. Elle peut avoir l’un de ces trois statuts :
- Running : les jobs se lancent et ne sont pas encore finis
- Passed : Tous les jobs sont passés
- Failed : Une erreur est survenue lors d’un ou plusieurs jobs, et vous pouvez voir les logs en cliquant sur le statut
Si on entre dans la pipeline en cliquant sur l’icône ronde indiquant qu’elle est en cours, on peut bien vérifier que deux jobs sont en train de tourner, et ils correspondent à ceux que l’on a définis :
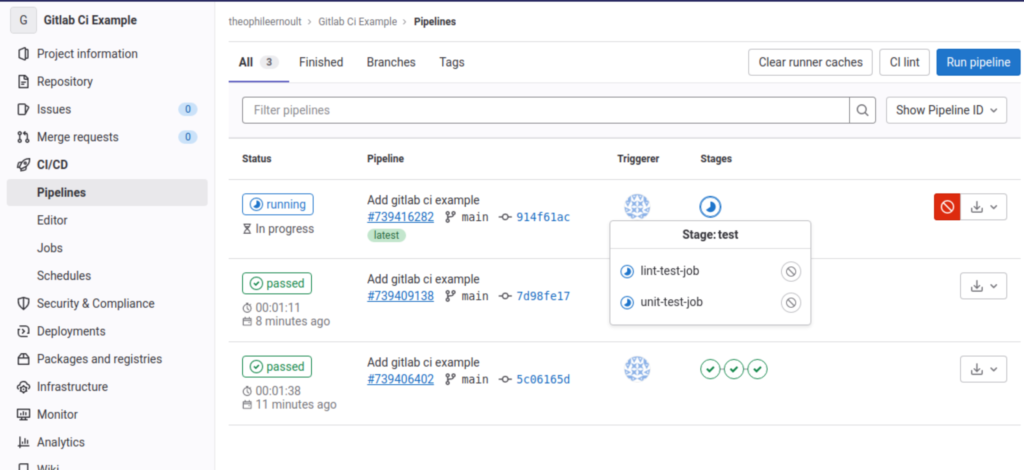
Cliquons par exemple sur le premier, et allons voir ce qu’il se passe à l’intérieur :
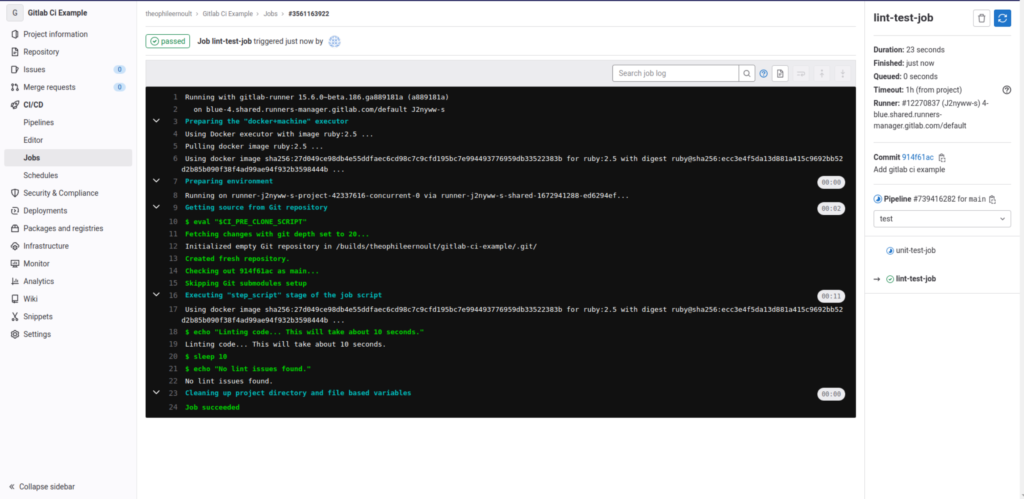
Que se passe-t-il ici ? Gitlab récupère les commandes que vous avez écrites dans votre .gitlab.ci correspondant à ce job, et va les exécuter, une à une, sur ses serveurs. Ce qu’il s’y passe dans le terminal interne au runner qui fait tourner votre script, est retransmis en temps réel, comme si vous étiez vous-même en train de les jouer. Ainsi, pour ce job, on peut bien retrouver nos commandes, et leurs résultat au fur et à mesure qu’elles sont lancées :
$ echo "Linting code... This will take about 10 seconds."
Linting code... This will take about 10 seconds.
$ sleep 10
$ echo "No lint issues found."
No lint issues found.Si des erreurs étaient survenues, elles seraient alors écrites, tout comme les succès.
Maintenant que nous avons vu cela, revenons à la liste des pipelines :
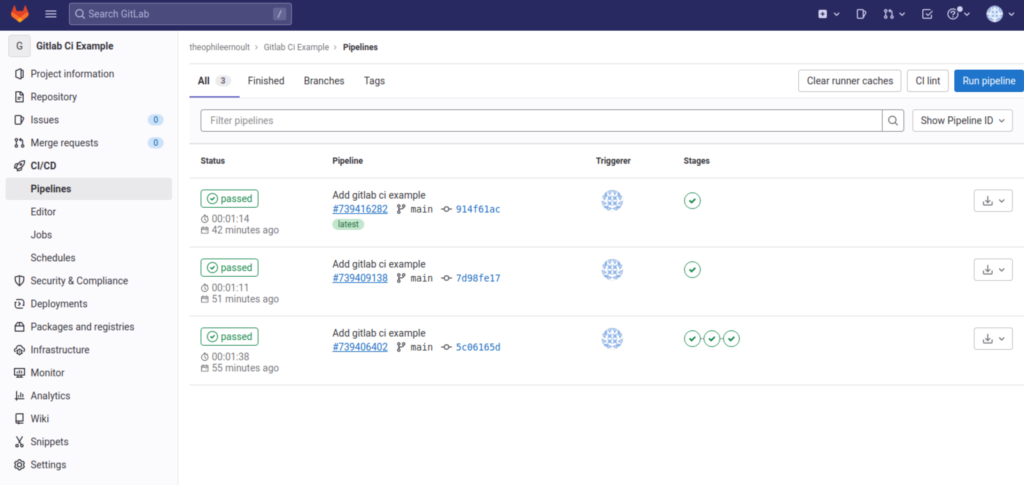
Vous pouvez vous apercevoir que de mon côté, j’ai plusieurs lignes présentes. EN effet, à chaque nouveau commit, la pipeline se lance. On peut d’ailleurs voir que la nôtre (la toute première) s’est bien terminée, et que les deux jobs ont réussi.
Votre pipeline est donc installée et prête à l’emploi.
Utilité et cas d’usage
Bon, c’est bien beau d’avoir une pipeline avec une icône verte et un statut « Passed », mais ça ne nous change pas la vie pour l’instant. À quoi est-ce que ça va bien pouvoir nous servir concrètement ?
Sécurité et évitement des régressions
Le premier intérêt d’avoir installé une intégration continue est de sécuriser votre application. En effet, imaginez que vous soyez sur un projet ou une dizaine voire une centaine de personnes travaillent au quotidien. Tout le monde a ses habitudes de code, et fait des erreurs. Un oeil humain peut le détecter à la lecture d’une merge/pull request, mais un oubli ou une inattention est vite arrivée, et du coce qui ne devrait pas se trouver dans votre branche cible risque de s’y glisser. À ce problème répond l’intégration continue, qui surveillera chacune des règles que vous aurez définies, et renverra un code d’erreur le cas échéant.
Pour l’instant, les règles que nous avons définies ne servent à rien, et étaient simplement lo pour tester le lancement des pipelines. Mais imaginons que nous mettions ceci en place :
stages: # List of stages for jobs, and their order of execution
- test
unit-test-job: # This job runs in the test stage.
stage: test # It only starts when the job in the build stage completes successfully.
script:
- echo "Running unit tests... This will take about 60 seconds."
- sleep 60
- echo "Code coverage is 90%"
lint-test-job: # This job also runs in the test stage.
stage: test # It can run at the same time as unit-test-job (in parallel).
script:
- echo "Linting code..."
- FIRST=$(head --bytes 5 app/index.php)
- if [[ $FIRST == "<?php" ]]; then exit 0; else exit 1; fiNous stipulons ici que dans le job de lint, nous allons vérifier que les 5 premiers caractères du fichier « app/index.php » valent bien « <?php ». En effet, si un fichier PHP ne commence pas par cette balise, votre application ne fonctionnera pas.
Je vais donc volontairement modifier l’index.php dans ce sens :
echo 'Hello World';
echo 'I have removed the PHP tag so the file will never work :/';Je vais mettre ce bout de code sur une nouvelle branche qui s’appellera « failure ». Et je push mon code, pour que la pieline se lance sur Gitlab.
Et sans surprise…
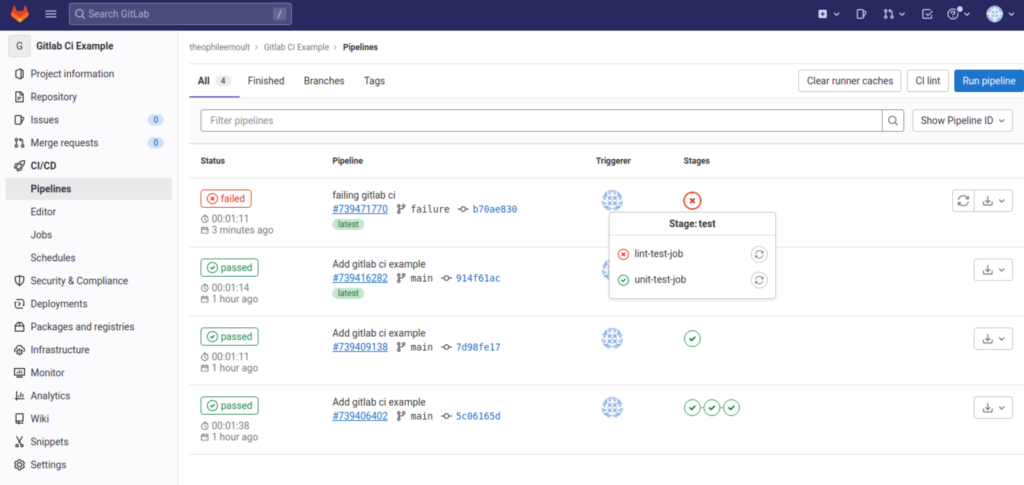
Elle s’est soldée par un échec.
Je parlais un peu plus tôt de sécurité, faisons un petit tour dans la section Settings > Merge request de Gitlab, et tout particulièrement à la rubrique Merge checks.
Vous y trouverez une option particulièrement intéressante, que nous allons tout de suite cocher. Elle s’appelle « Pipelines must succeed«
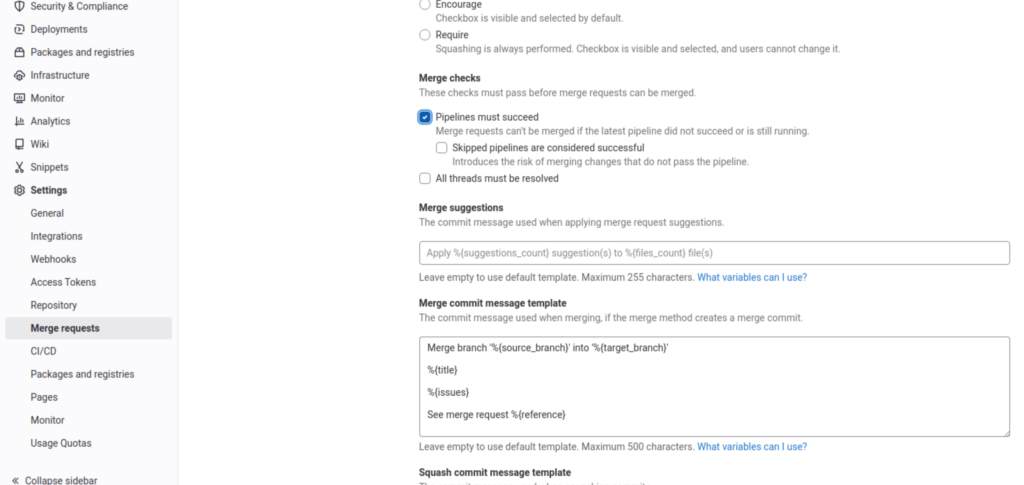
Cette option, une fois activée, ne permettra pas de pouvoir accepter une merge/pull request lorsque la pipaline associée n’est pas passée. Ce qui vous GARANTIT que le code qui sera mergé respectera les règles définies dans votre .gitlab.ci
Et, en effet, si nous revenons à notre branche failure, et que nous tentons d’ouvrir une merge request vers la branche main…
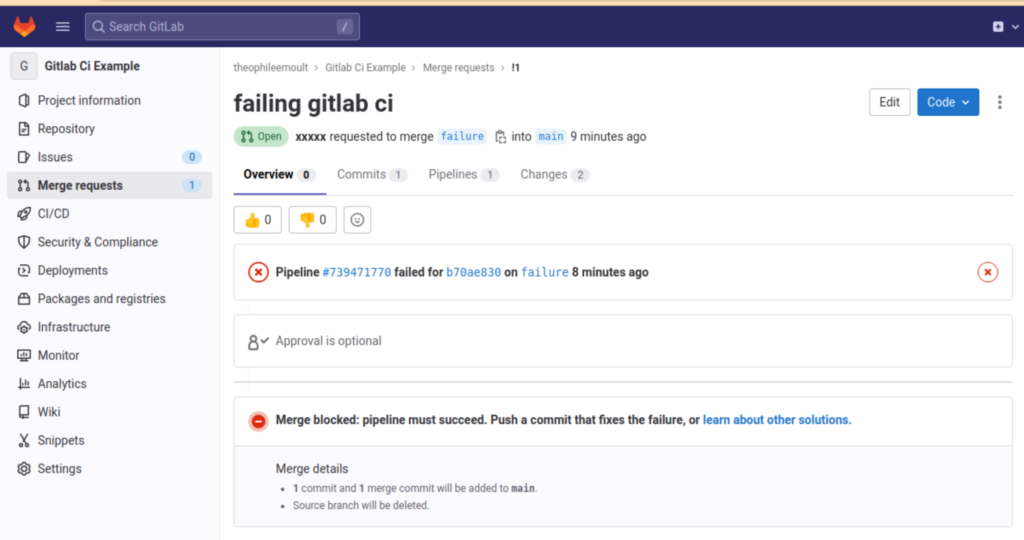
La fusion est impossible, tant que nous n’avons pas poussé un nouveau commit, qui fera repasser la pipeline dans un état de succès. On va donc remettre notre balise manquante sur notre code et créer un nouveau commit :
<?php
echo 'Hello World';
echo 'better :)';La pipeline est maintenant réparée, et le merge est à nouveau possible :
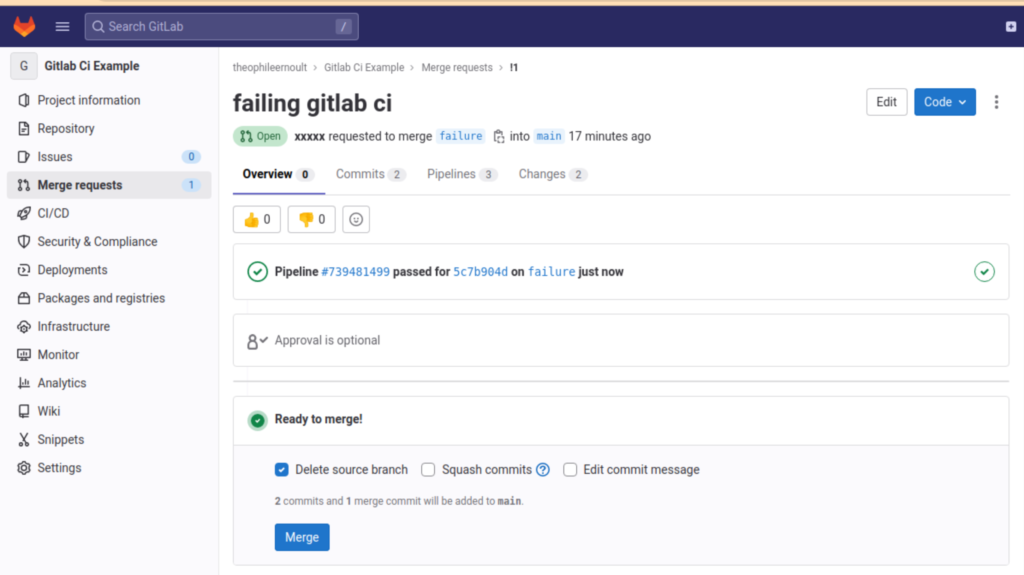
Aller plus loin
Nous avons vu comment configurer un simple fichier d’intégration continue, pour un cas d’usage tout à fait basique. En réalité, lors de la review d’un bout de code, il est quasiment impossible de laisser passer une faute aussi grosse qu’une balise « <?php » qui aurait disparu, d’autant qu’un simple coup d’œil sur la page en question vous permet de voir que quelque chose n’est pas normal.
Néanmoins, cet article vous donne les bases pour déclencher des scripts automatisés lors de chacun de vos commits. La limite d’utilisation n’est bornée qu’à votre imagination. Parmi les tests et jobs les plus courants, on peut citer :
- Le lint de code avec des outils dédiés (PHPStan, PHPcs, ESLint pour le javascript…)
- Les tests automatisés avec PHPUnit, vous permettant d’écrire de vrais scénarios pour des sites plus ou moins complexes, avec gestion de vos bases de donnees etc…
- Le déploiement continu de vos branches (CD) sur un serveur dédié
- Le lancement d’une pipeline précise pour une branche/un tag spécifique
- Toute commande que vous faites en bash peut y être insérée
- …
Je vous invite fortement à aller lire la documentation officielle de Gitlab pour en savoir plus sur le sujet, et d’ici là, bon code !
Thx